- Exemplo: Determinar se um modelo tem "boa" exatidão
- Precauções na utilização da exatidão para avaliar o desempenho do modelo
Ao utilizar modelos de classificação na aprendizagem automática, uma métrica que utilizamos frequentemente para avaliar a qualidade de um modelo é exatidão .
A precisão é simplesmente a percentagem de todas as observações que são corretamente classificadas pelo modelo.
É calculado da seguinte forma:
Exatidão = (número de verdadeiros positivos + número de verdadeiros negativos) / (dimensão total da amostra)
Uma questão que os alunos têm frequentemente sobre a exatidão é:
O que é considerado um "bom" valor para a precisão de um modelo de aprendizagem automática?
Embora a exatidão de um modelo possa variar entre 0% e 100%, não existe um limiar universal que possamos utilizar para determinar se um modelo tem ou não uma "boa" exatidão.
Em vez disso, normalmente comparamos a precisão do nosso modelo com a precisão de um modelo de base.
Um modelo de base é aquele que prevê simplesmente que todas as observações num conjunto de dados pertencem à classe mais comum.
Na prática, qualquer modelo de classificação que tenha uma precisão mais elevada do que um modelo de base pode ser considerado "útil", mas, obviamente, quanto maior for a diferença de precisão entre o nosso modelo e um modelo de base, melhor.
O exemplo seguinte mostra como determinar aproximadamente se um modelo de classificação tem uma precisão "boa" ou não.
Exemplo: Determinar se um modelo tem "boa" exatidão
Suponhamos que utilizamos um modelo de regressão logística para prever se 400 jogadores de basquetebol universitário diferentes são ou não seleccionados para a NBA.
A matriz de confusão seguinte resume as previsões efectuadas pelo modelo:
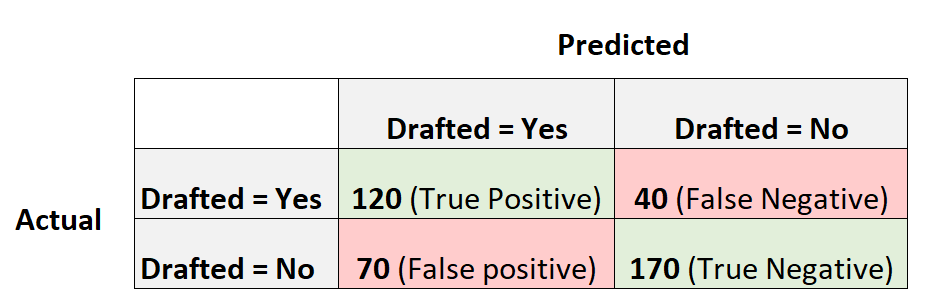
Eis como calcular a exatidão deste modelo:
- Exatidão = (número de verdadeiros positivos + número de verdadeiros negativos) / (dimensão total da amostra)
- Precisão = (120 + 170) / (400)
- Exatidão = 0.725
O modelo previu corretamente o resultado para 72.5% de jogadores.
Para ter uma ideia se essa precisão é ou não "boa", podemos calcular a precisão de um modelo de base.
Neste exemplo, o resultado mais comum para os jogadores foi não serem recrutados, ou seja, 240 dos 400 jogadores não foram recrutados.
Um modelo de base seria um modelo que previsse simplesmente que todos os jogadores não seriam seleccionados.
A exatidão deste modelo seria calculada como:
- Exatidão = (número de verdadeiros positivos + número de verdadeiros negativos) / (dimensão total da amostra)
- Precisão = (0 + 240) / (400)
- Exatidão = 0.6
Este modelo de base preveria corretamente o resultado para 60% de jogadores.
Neste cenário, o nosso modelo de regressão logística oferece uma melhoria notável na precisão em comparação com um modelo de base, pelo que consideramos que o nosso modelo é, pelo menos, "útil".
Na prática, é provável que ajustemos vários modelos de classificação diferentes e escolhamos o modelo final como aquele que oferece o maior aumento de precisão em comparação com um modelo de base.
Precauções na utilização da exatidão para avaliar o desempenho do modelo
A exatidão é uma métrica comummente utilizada porque é fácil de interpretar.
Por exemplo, se dissermos que um modelo tem 90% de precisão, sabemos que classificou corretamente 90% das observações.
No entanto, a exatidão não tem em conta a forma como os dados são distribuídos.
Por exemplo, suponhamos que 90% de todos os jogadores não são seleccionados para a NBA. Se tivermos um modelo que preveja simplesmente que todos os jogadores não serão seleccionados, o modelo preveria corretamente o resultado para 90% dos jogadores.
Este valor parece elevado, mas o modelo não é capaz de prever corretamente qualquer jogador que seja recrutado.
Uma métrica alternativa que é frequentemente utilizada é a chamada Pontuação F1 que tem em conta a forma como os dados são distribuídos.
Por exemplo, se os dados forem altamente desequilibrados (por exemplo, 90% de todos os jogadores não são seleccionados e 10% são seleccionados), então a pontuação F1 fornecerá uma melhor avaliação do desempenho do modelo.
Leia mais sobre as diferenças entre precisão e pontuação F1 aqui.