A residual é a diferença entre um valor observado e um valor previsto num modelo de regressão.
É calculado da seguinte forma:
Residual = Valor observado - Valor previsto
Se traçarmos os valores observados e sobrepusermos a linha de regressão ajustada, os resíduos para cada observação seriam a distância vertical entre a observação e a linha de regressão:
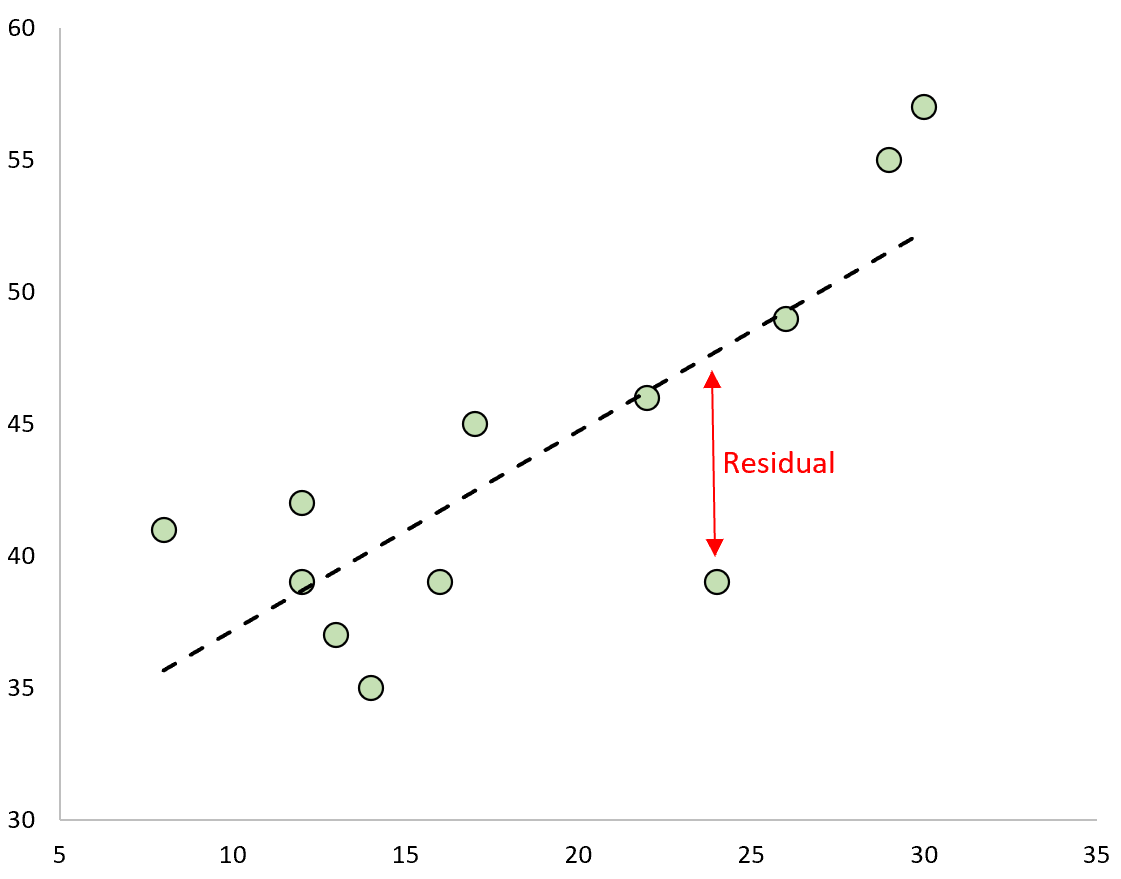
Um tipo de resíduo que utilizamos frequentemente para identificar outliers num modelo de regressão é conhecido como resíduo padronizado .
É calculado da seguinte forma:
r i = e i / s(e i ) = e i / RSE√ 1-h ii
onde:
- e i : O i-ésimo resíduo
- RSE: O erro-padrão residual do modelo
- h ii O efeito de alavanca da i-ésima observação
Na prática, consideramos frequentemente que qualquer resíduo padronizado com um valor absoluto superior a 3 é um valor atípico.
Isto não significa necessariamente que vamos remover estas observações do modelo, mas devemos pelo menos investigá-las melhor para verificar se não são o resultado de um erro de introdução de dados ou de outra ocorrência estranha.
Nota: Por vezes, os resíduos normalizados são também designados por "resíduos estudados internamente".
Exemplo: Como calcular resíduos padronizados
Suponhamos que temos o seguinte conjunto de dados com um total de 12 observações:

Se utilizarmos algum software estatístico (como o R, Excel, Python, Stata, etc.) para ajustar uma linha de regressão linear a este conjunto de dados, descobriremos que a linha de melhor ajuste é:
y = 29,63 + 0,7553x
Utilizando esta linha, podemos calcular o valor previsto para cada valor Y com base no valor de X. Por exemplo, o valor previsto da primeira observação seria:
y = 29.63 + 0.7553*(8) = 35.67
Podemos então calcular o resíduo para esta observação como:
Residual = Valor observado - Valor previsto = 41 - 35,67 = 5.33
Podemos repetir este processo para encontrar o resíduo para cada observação:

Também podemos utilizar software estatístico para determinar que o erro padrão residual do modelo é 4.44 .
E, embora esteja fora do âmbito deste tutorial, podemos utilizar software para encontrar a estatística de alavancagem (h ii ) para cada observação:

Podemos então utilizar a seguinte fórmula para calcular o resíduo padronizado para cada observação:
r i = e i / RSE√ 1-h ii
Por exemplo, o resíduo padronizado para a primeira observação é calculado como:
r i = 5.33 / 4.44√ 1-.27 = 1.404
Podemos repetir este processo para encontrar o resíduo padronizado para cada observação:
Podemos então criar um gráfico de dispersão rápido dos valores do preditor vs. resíduos padronizados para ver visualmente se algum dos resíduos padronizados excede um limite de valor absoluto de 3:

A partir do gráfico, podemos ver que nenhum dos resíduos padronizados excede um valor absoluto de 3. Assim, nenhuma das observações parece ser anómala.
Nalguns casos, os investigadores consideram que as observações com resíduos normalizados que excedem um valor absoluto de 2 são consideradas anómalas.
Cabe ao utilizador decidir, dependendo da área em que trabalha e do problema específico em que está a trabalhar, se deve utilizar um valor absoluto de 2 ou 3 como limite para os valores atípicos.